When Performance Stops Being a Number
Curiosity & GO
Soooo a friend of mine recently shared about how her Go Server was sooo fast it self-DDoSed her laptop.
She had created a high-throughput Auction Engine built in Go, which handles 650k+ RPM with 100% success rate by optimizing the Windows TCP stack and leveraging Redis Lua atomicity.
My curiosity hit up with questions such as, why not Linux?
What happens if I change the OS and load shape?
And rather than saying, Linux better, lol, I decided to do some experiments.
The original experiment focused on Windows behavior under bursty load.
In this post, I reproduce the same benchmark on Fedora Linux and extend the analysis across different pacing and load shapes (burst vs sustained) to understand how OS-level behavior and workload shape influence system bottlenecks.
I cloned the source code repository on my Fedora.
Specs:
- OS: Fedora Linux 40 (Workstation Edition)
- Kernel: 6.14.5-100.fc40.x86_64
- CPU: AMD Ryzen 7 5800HS (8 cores / 16 logical CPUs)
- Memory: 16 GB
- Go: go1.25.5
- Redis: 7.x (local, single instance)
- Network: loopback (127.0.0.1)
If I remember correctly, Linux has a much more mature TCP stack than Windows, so I understand the original aim was to have a Go vs Python performance trade-off and limitations of the Windows TCP stack.
So I experimented on fedora with
3 ms->2 ms->1 ms->0 ms
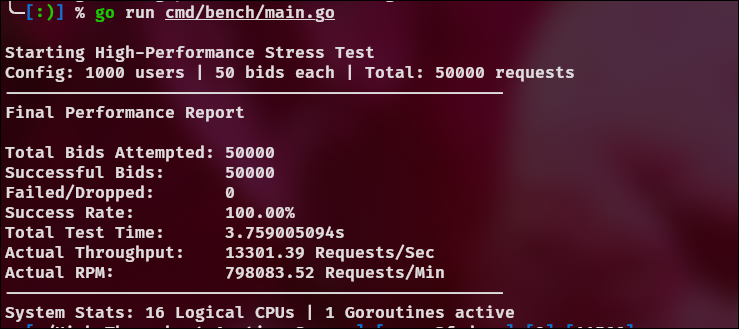
3 ms:
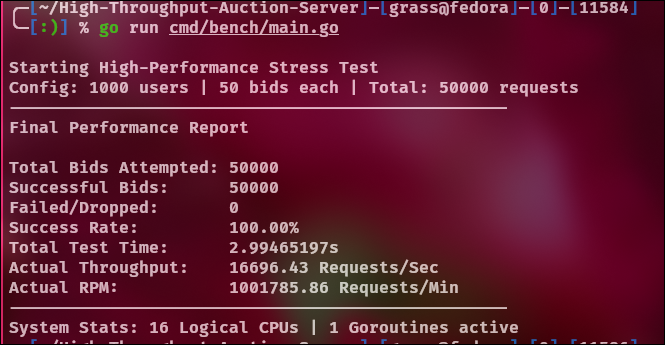
2 ms:
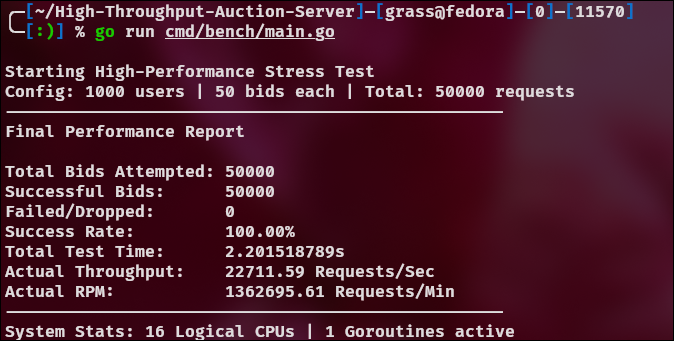
1 ms:
Once again:
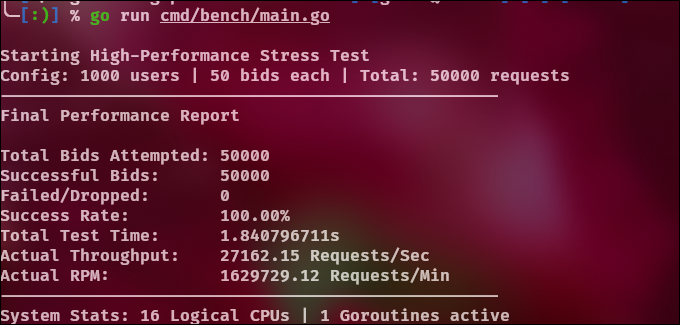
0 ms:
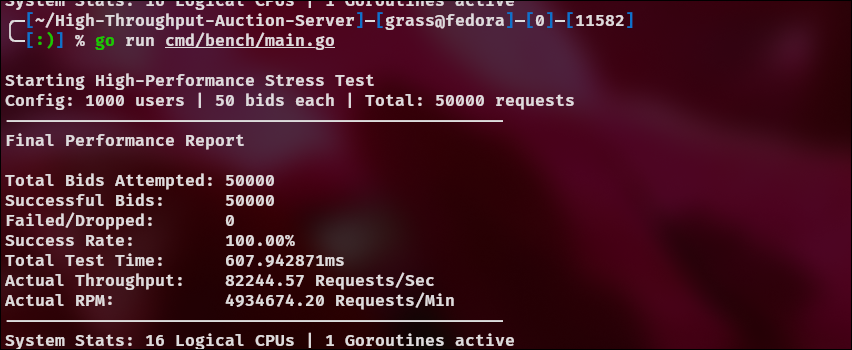
Same Go server, same benchmark, different OS → different optimal pacing.
Running the same Go server and benchmark on Linux revealed a different optimal pacing window, highlighting how OS-level TCP behavior can dominate system performance.
One more run with 0 ms just to confirm,
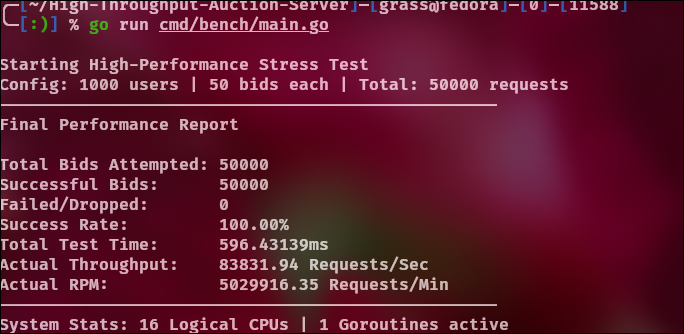
The benchmark finished so fast that TCP never collapsed.
Findings ?
Linux can:
- absorb very large SYN bursts
- batch socket wakeups efficiently
- handle localhost traffic extremely well
Windows could not do this in the original experiment, which is why:
- 0 ms pacing on Windows → SYN collapse
- 0 ms pacing on Linux → clean completion
What changed at 0 ms pacing
When we removed pacing, we did not make the system infinitely parallel.
We created a huge instantaneous burst.
That shifts the bottleneck from:
- TCP accept path (earlier)
to - user-space + kernel contention
Learning Takeaways
We observed the total test time has decreased sooo much for 0 ms!
WHYYYY?
Cuz
Goroutine scheduling is under pressure! 1000 clients wake up together And then Go has to enqueue them, do context switch and then manage run queues. And realistically, it costs time even tho CPU cores don’t max out. Scheduler overhead ≠ CPU saturation.
Redis serialization SO when we use Lua it executes everything serially. Now Redis becomes kind of the choke point i assume. Adds latency even tho we have a crazy good throughput.
TCP slow starts and we have some socket buffers, like yea, Linux handles them well, but not for free.
Also we should remember the total test time obv isn’t server alone, it includes nitty gritty stuff of client side also.
Conclusively, 1-2 ms pacing is optimal on Linux, it addresses and resolves all of the above.
COOL THINGS TO NOTE:
- Linux TCP stack does not collapse
- Go runtime stays stable
- Redis survives the burst
- No packet loss, no failures
The extra ~600 ms is simply:
the cost of coordinating extreme parallelism.
Yea, it is healthy and not toxic. (lmao)
So next let’s try a different load shape: Does Linux still win when the load is sustained, and not instantaneous?
Right now the bids are sent in a bursty fashion, can we check if I send it over with same users, same bids, but bids are spread over some time?
So let’s experiment and change in bench/main.go, from 10 ms to 400ms (basically 50 bids x 400ms=20sec).
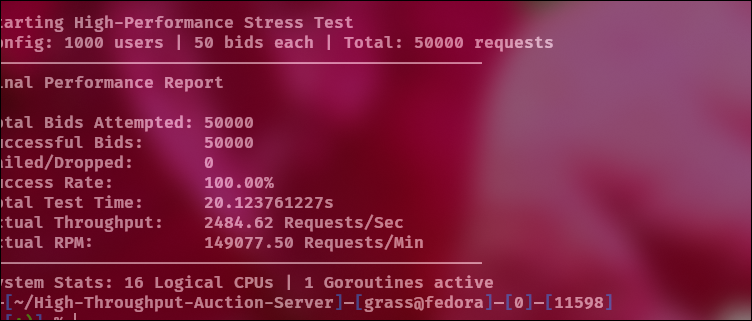
Load average: 2-3 at all times, which is honestly really good.
Yes, we have understood now that Linux has stayed calm even during a sustained load. This shows reliability.
Earlier (burst / 0ms):
- Huge RPM
- Finished in <1s
- Everything happened at once
Now (sustained):
- Much lower RPM
- Much longer runtime
- Load spread evenly
This is not worse. It kind of proved the point of the system staying healthy over time.
Okay, we got lil side-tracked just for personal curiosity and yes, let’s get back to track.
Bottleneck now shifts from TCP accept to application level throughput i.e. Redis and scheduling stuff.
We still have a lot of CPU lying around to be used.
Formally speaking, under sustained load with long-lived connections, the system remains stable on Linux with low CPU utilization; throughput is limited by the client-side bid rate rather than the OS or server.
Ground truths learnt:
- Burst tests measure a system’s ability to absorb chaos, not to do work efficiently.
- Most production systems fail here, not because they are slow, but because they degrade silently.
Personal note:
I learned that systems don’t have a single performance truth.
They behave differently, under parameters.Burst loads test admission control and OS policy.
Sustained pressure tests coordination and shared resources.
Realistic load tests trustworthiness, not speed. (I always thought it was all bout speed like a kid)Every time I removed one bottleneck, another emerged higher in the stack.
That wasn’t failure, that was the system revealing itself.Performance isn’t about making numbers bigger.
It’s about understanding which layer is limiting me and why.
THIS felt like the network stack revealed itself to me today once again. And with this, my curiosity is fulfilled for now :))
This post builds on Prachi Jha’s experiment on a high-throughput Go auction server, where Windows TCP admission behavior became the primary bottleneck under burst load. I reproduced the same benchmark on Fedora Linux to study how the system behaves under different operating system constraints and workload shapes.
Checkout her writeup!
My Go Server was so fast it self-DDoS’d my laptop